

Data Merging¶
Data Merging is a method of submitting contributions to a data science project. In fact, it is the natural extension of a regular code merge, when using a data versioning system in addition to your regular git repository.
How Does Data Merging works?¶
File changes¶
When you open a data science pull request in your project, DagsHub detects the changes in the cached files of your DVC project and displays the list of changed files in the Files changed tab of the data science pull request.
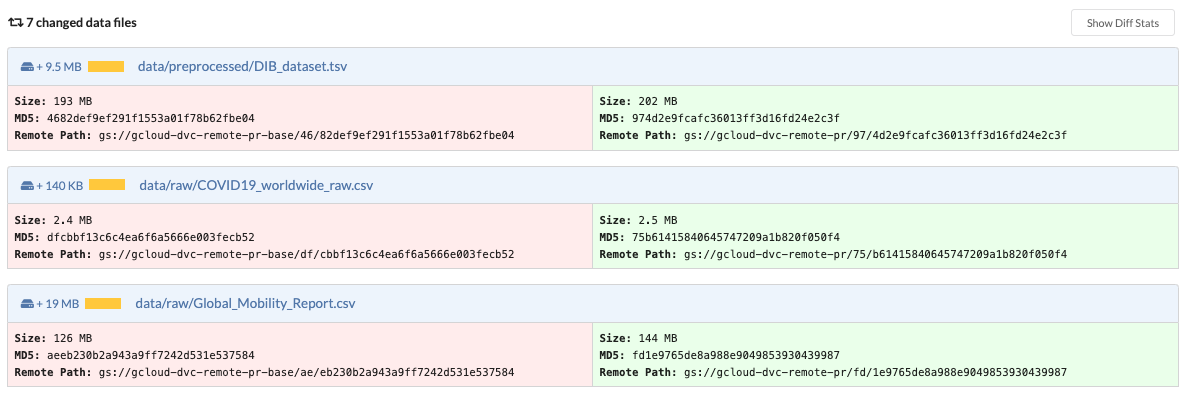
Data diff¶
DagsHub retrieves additional information on the files:
- File Size
- Directory Content - When you define a directory as a DVC cached output or dependency, DagsHub will list the changed files inside the directory.
In order to get the full benefits of the feature, both the base repository and the head repository of a data science pull request need to have a Storage Access Key configured.
Data merge¶
DagsHub can copy new cache data from one remote to another!
In order for anybody to collaborate on a DVC project today, every potential contributor needs to have permissions to write to the same remote cache. This is no longer the case. Everybody can open a data science pull request from their forked repository, and you can safely decide if you want to merge the changes in the code as well as the changes in the data.
In order to use the data merge properly, both these conditions need to be fulfilled:
- The base repository has a Storage Access key configured with write permissions
- The head repository has a Storage Access key configured with at least read permissions
Data Merging - Supported storage types¶
The storage types currently supported are (click the link to learn how to set up): - DagsHub Storage - AWS S3, Google Cloud Storage, and S3-compatible storage
We are working on adding support for additional storage types. If you have specific request feel free to send us Feedback or join the community and ask directly.