

Data Engine¶
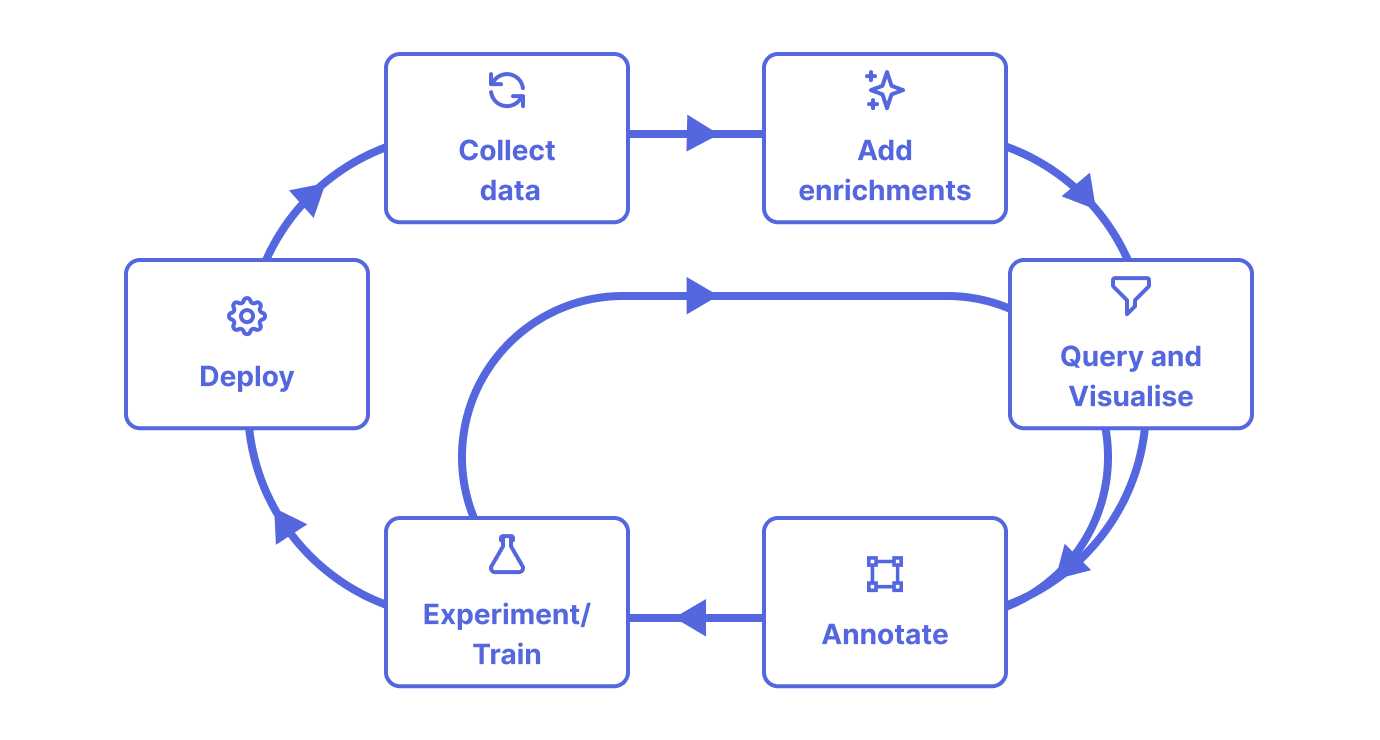
Data Engine is a toolset built to make iterating on unstructured datasets easy by providing a seamless flow to create training ready datasets. The flow includes:
- Collecting data from different sources and enriching it with custom metadata, annotations, and predictions
- Querying your data to easily create subsets for different use cases
- Visualizing your datasets to analyze and understand your data
- Annotating relevant data points
- Generating training-ready datasets to retrain your model on
- Tracking your dataset & model lineage
Data Engine Architecture¶
Data Engine includes a few important components covered below:
Enrichments¶
Data Engine works with your data and enrichments. Enrichments are metadata fields that include extra information about a data file, like its size, location, from which customer the data was received, and other details. They can also include annotations and predictions made by models.
Data Engine supports almost any enrichment type, including numbers, strings, and booleans, but also arbitrary binary data, so you can add custom annotation formats, images, or pickle files as enrichments too. This means you can associate the metadata you need with your data, without worrying you’ll need to manage it in a custom way for each unique column. It just works. Enrichments are all attached to their corresponding data points which live inside a data source.
In addition to enrichments, there are three main classes that are used to query, visualize, annotate, and regenerate data.
Datasource show source¶
The top-level class of the Data Engine represents the source of the data points. It contains the data points and their
enrichments. Datasources are queryable, meaning you can filter them to create subsets. When you run a query on a
datasource, e.g. q = ds['size'] < 5 the returned object is another datasource. You can also add the enrichments
mentioned above. After a Datasource is queried, you can save it as a dataset.
QueryResult show source¶
When you’ve set up your datasource and filters, you can get the appropriately filtered datapoints using all() which
returns all datapoints, or head() which returns a sample of datapoints (100 by default). When you run q.all()
or q.head() the returned object is a QueryResult. You can use it to transform the results into a
dataframe, visualize them
, convert them to a dataloader, or download the relevant files locally.
Datapoint show source¶
Represents a single data file and its associated enrichments. Data points can be downloaded individually, and their
metadata can be accessed similar to a dict.
Here is a simple example on creating a dataframe from a datasource:
from dagshub.data_engine import datasources
# Create a datasource from the 'dataset/' folder in a repo it
ds = datasources.create_from_repo(repo="<repo_owner>/<repo_name>", name="my-dataset", path="dataset")
# Get the first 100 datapoints
query_res = ds.head()
# Create a pandas data frame from the query results
df = query_res.dataframe
print(df)
Next Steps¶
Take your next steps with Data Engine by learning how to create training ready datasets with Data Engine.