


Using GitHub for Machine Learning - The Good, The Bad & The Ugly
Nowadays, I see a lot of “open source” ML projects trying to harness the power of the open source community on GitHub and promote open ML. While their heart is in the right place, in practice these projects often fail to really be open source or end up exposing projects component in funky ways.
This is not because of bad intentions, but because of limitations inherent to GitHub when it comes to the machine learning development process, which is different in a lot of ways from regular software development.
| Stuff to keep track of | Software Development | ML Development |
|---|---|---|
| Code | ✅ | ✅ |
| Data | ✅ | |
| Hyperparameters | ✅ | |
| Data Labels | ✅ | |
| Models | ✅ | |
| … | ✅✅✅ |
In this blog, I will go over those limitations, and present some free tools that help us deal with those limitations and make our workflow smooth, efficient, open, and collaborative.
So if you host your code on GitHub, but you’re still using google drive to store your models and a spreadsheet to track your experiments, keep reading.
The Good
Back in 2008, GitHub revolutionized the world of open source development (and software development in general) by creating a web service surrounding Git. Introduced three years prior, Git was a new, free & open source version control software, with the potential to change the world. The creators of GitHub took Git and built an amazing collaboration system surrounding the open source tool.
Since then, GitHub has become the standard place to host open source projects and collaborate, and it’s not for nothing. We can utilize a lot of the tools GitHub provides for our own machine learning projects.
Git Versioning & Hosting
We all need a place to put our code. Versioning our code with Git helps us be sure we can always go back in time if something happens.
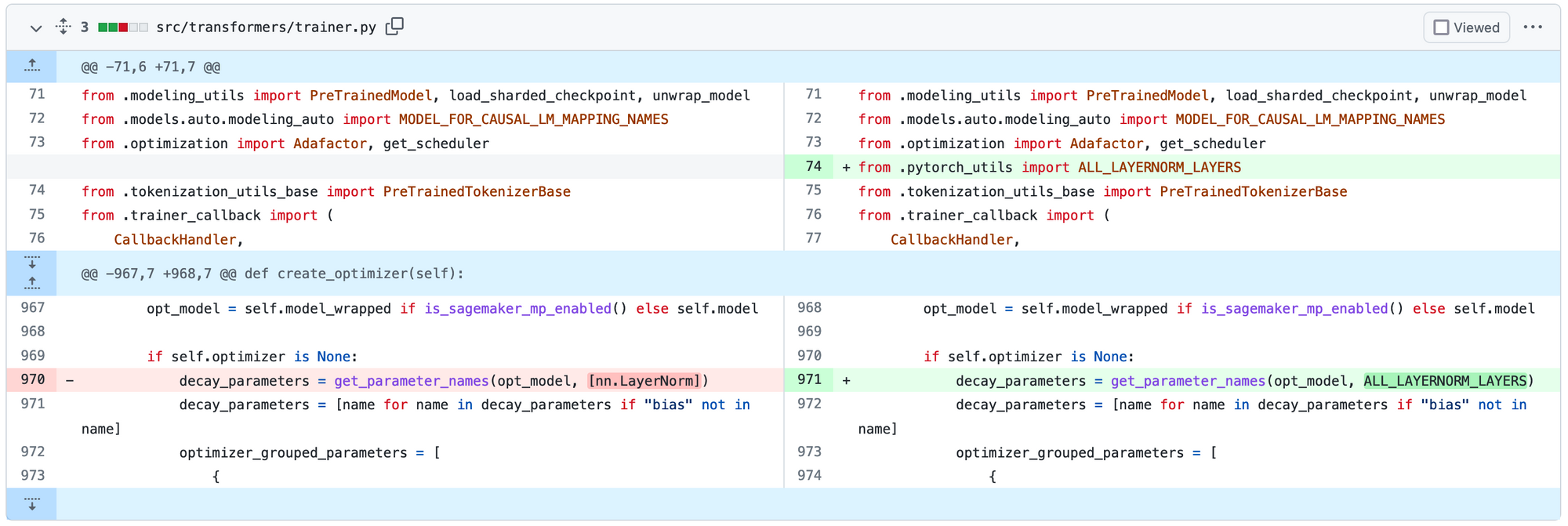
GitHub has always provided a nice UI to view all the committed code and versions tracked by Git. Furthermore, hosting in a public space like GitHub lets everyone see our progress.
Issues, Pull Requests, and Code reviews
GitHub has built an amazing workflow that has proved itself even when working on open source projects with hundreds of collaborators that have never met in person.
Issues allow everyone, and I mean EVERYONE, to raise problems & suggestions and discuss them.
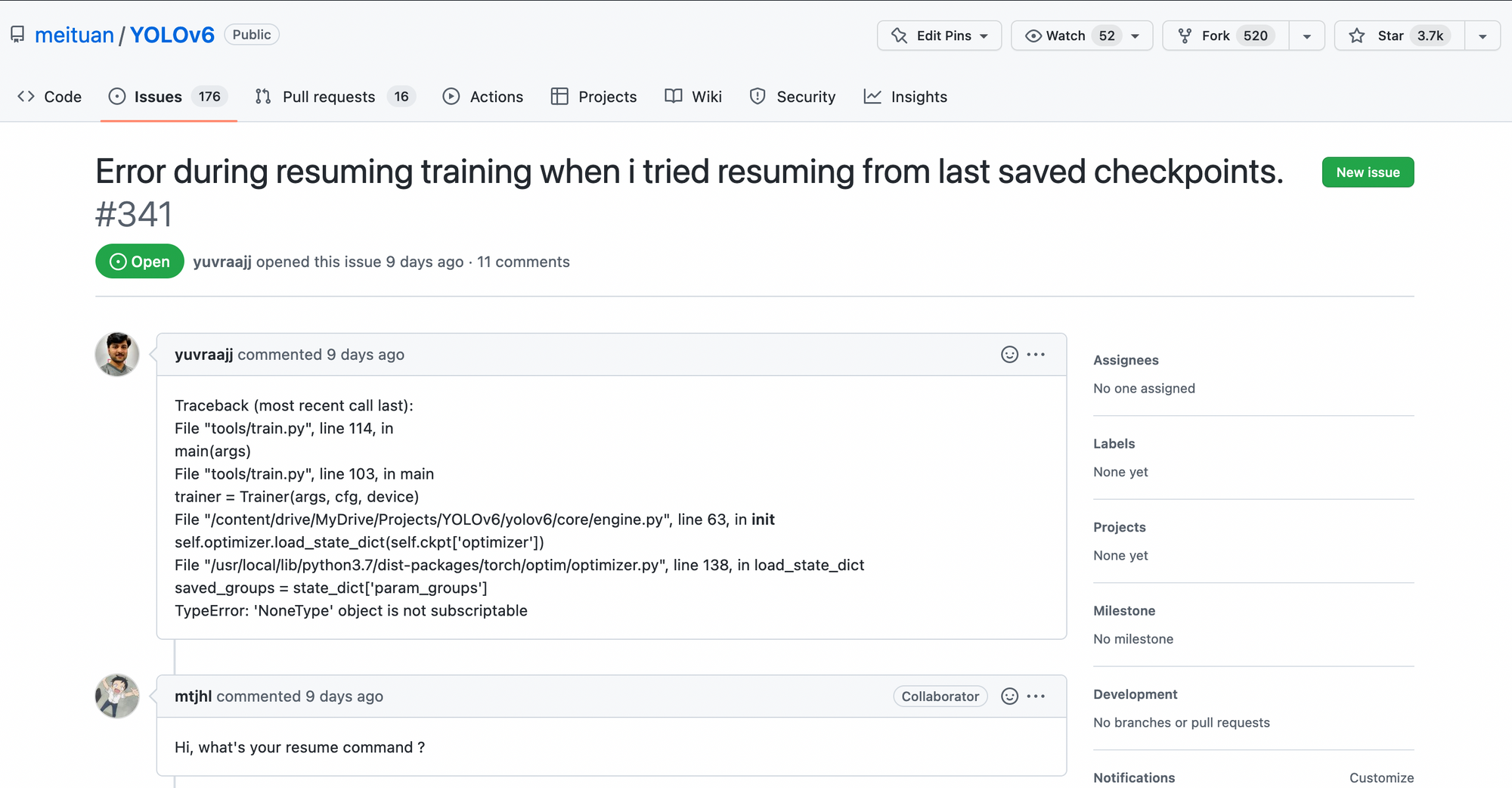
Users can report bugs, discuss problems, find solutions, and help others! Issues are also used by users and maintainers of the open source project to document ideas and suggestions.
When someone wants to fix an issue, they can fork the project and open a Pull Request.
A pull request lets maintainers see the code changes and do a Code Review. While this is great in cases when only changes to code are required, things begin to fall apart when changes are made to the data or model. But more on that later.
GitHub Actions
GitHub actions is a free CI/CD tool that GitHub provides. GitHub actions can be useful for:
- Testing new code before it is merged
- Running training automatically
- Deploying new changes automatically
This is not a blog about using GitHub actions for ML, but there are some awesome resources about it:
- Data Testing for Machine Learning Pipelines Using Deepchecks, DagsHub, and GitHub Actions
- Automating data validation with GitHub Actions
- Deploy Your ML Model with GitHub Actions
- Manage ML Automation Workflow with DagsHub, GitHub Action, and CML
- Machine Learning Ops by GitHub
- GitHub Actions for Machine Learning: Train, Test and Deploy Your ML Model on AWS EC2.
The Bad
Although GitHub is an amazing tool for collaborating on software projects, machine learning development is just inherently different. Working with HUGE datasets, running experiments and labeling data are just things Git and GitHub weren’t made to handle. Luckily for us, just like Git solved code versioning & collaboration, there are a lot of great new open source tools that can help us with each of the new challenges machine learning collaboration presents.
BIG Files
Since GitHub repositories are based on Git, and Git can’t handle large files, we can’t use it alone to upload and track our data & models, which are often big binary files. Luckily, there are some other open source tools to save the day!
DVC - Data, Models, Pipeline Versioning
DVC takes the best of Git and applies it to large file storage. It uses your Git repository to store meta files and an external cloud storage to store the actual BIG files.
That way, we get all the benefits of Git versioning with the ability to now apply it to our data & models.
Experiment Tracking
When working on an ML project, we have yet another part of the equation to take into consideration, our hyperparameters. To ensure we are getting the best result, experiment tracking is a must! If you’re still using a spreadsheet for this purpose, you gotta read this.
Git
Yes, you read correctly! We can actually use Git for our experiment tracking. Bear in mind GitHub doesn’t have a native modern way to display those experiments and you may need to use another platform (🐶) for that.
There are several open source tools that let you track your experiments with Git.
DVC, again, is one of them and another is our personal favorite, the DagsHub logger.
With either one, your experiments are saved as metrics and params files in your Git repository. This allows you to version them and reproduce past results easily.
$ dvc exp show
─────────────────────────────────────────────────────────────────────────────────────────────
Experiment Created loss acc train.epochs model.conv_units
─────────────────────────────────────────────────────────────────────────────────────────────
workspace - 0.25183 0.9137 10 64
mybranch Oct 23, 2021 - - 10 16
├── 9a4ff1c [exp-333c9] 10:40 AM 0.25183 0.9137 10 64
├── 138e6ea [exp-55e90] 10:28 AM 0.25784 0.9084 10 32
└── 51b0324 [exp-2b728] 10:17 AM 0.25829 0.9058 10 16
─────────────────────────────────────────────────────────────────────────────────────────────
MLflow Tracking
MLflow is an open source ML platform that has many components, but for now, let’s focus on its experiment tracking abilities.
import mlflow
# Log parameters (key-value pairs)
mlflow.log_param("num_dimensions", 8)
# Log a metric; metrics can be updated throughout the run
mlflow.log_metric("accuracy", 0.1)
Unlike the previous methods, MLflow provides a built-in UI for exploring the experiments! This is very handy but requires more setup. And if you’re working with a team, you’re looking at a task that requires a DevOps degree.
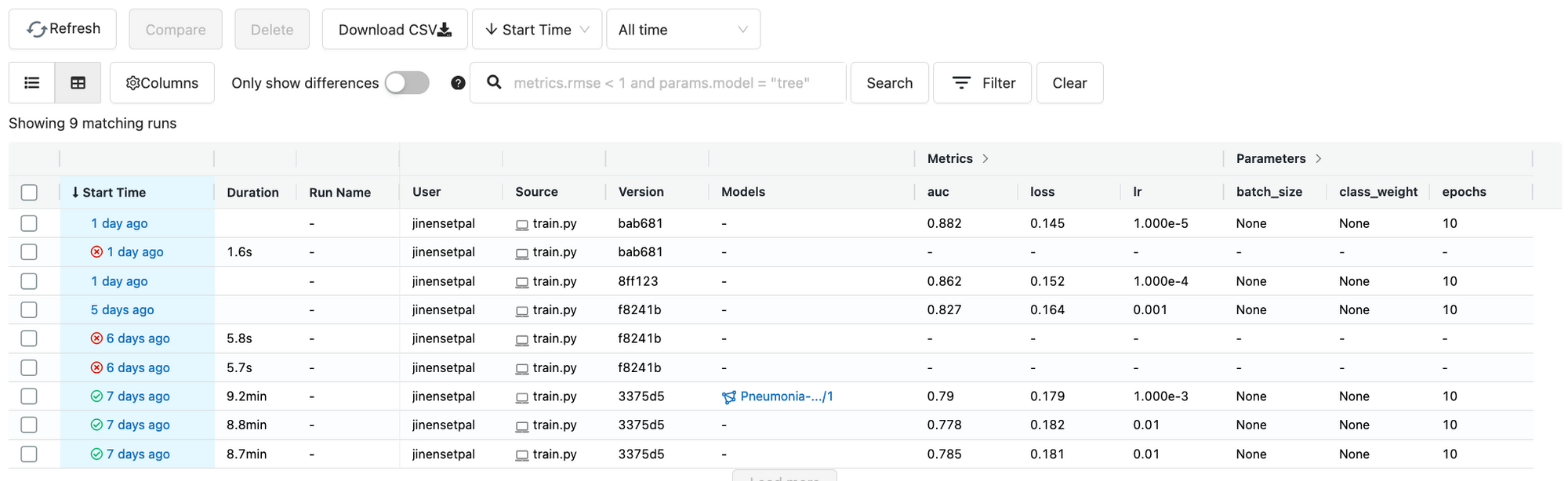
Weights & Biases
W&B is not open source but is very popular and free for the community & academics.
Weights & Biases provides both a python library for simple experiment tracking and a beautiful web UI to view & explore them.
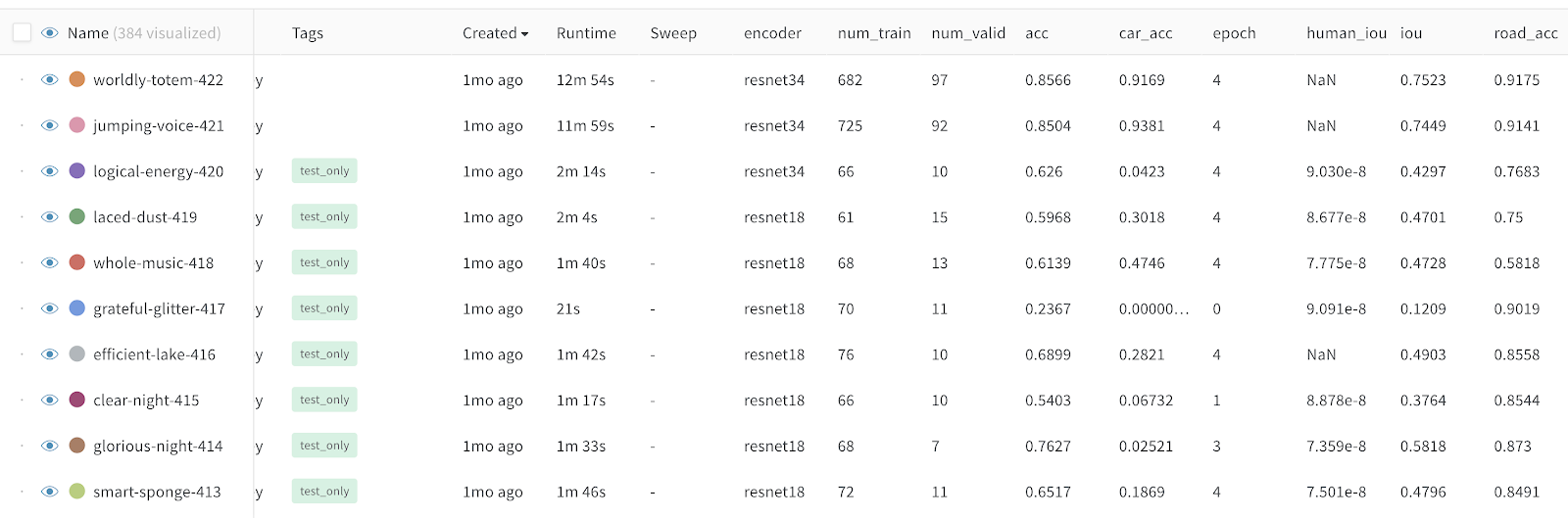
Read more in the docs
Data Labeling
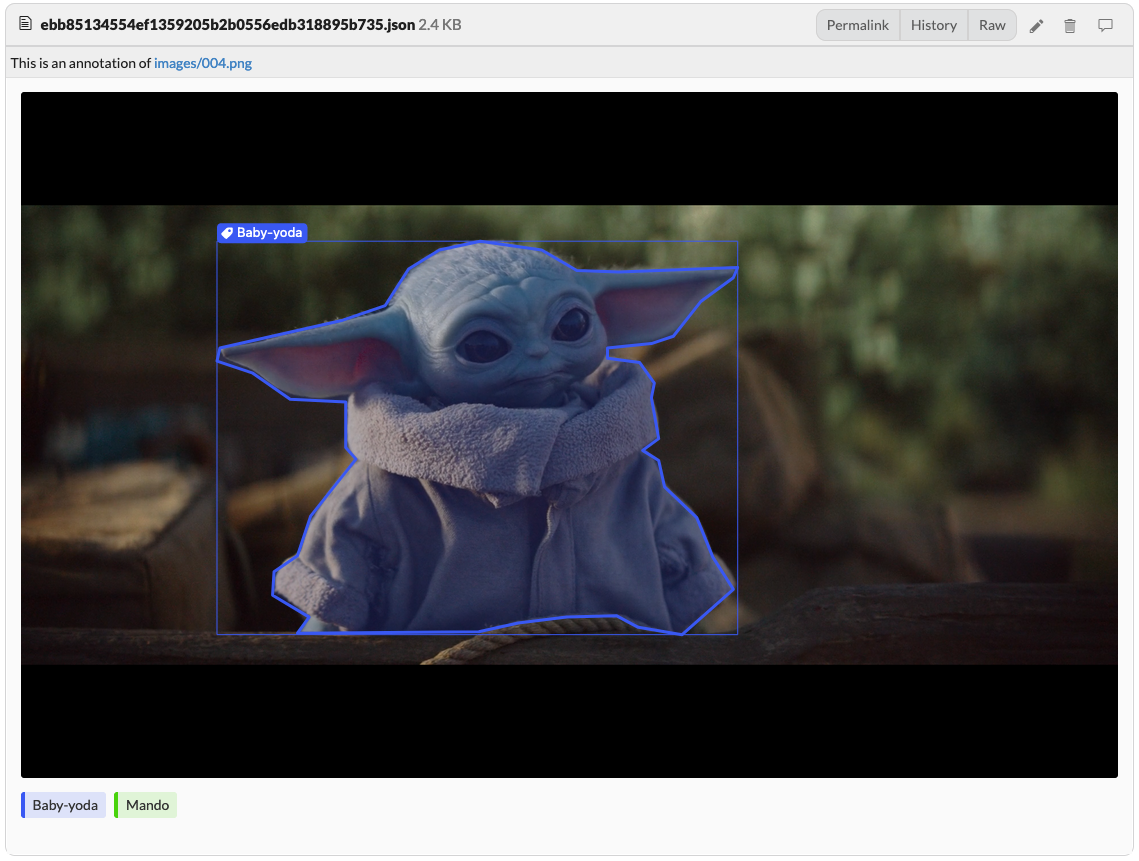
Labeling is often an important and time-consuming part of our ML workflow. While it might sound odd to use GitHub for data annotations, we can actually get a lot of benefit from it.
Just like with our code, data, models, and experiments, we’d ideally want to version and review our labels. Data annotations are added, modified, and corrected over time and therefore extremely important to version in order to enable reproducibility of our models and results.
I’m not going to go into too much depth here, since most annotation tools are not natively connected to git and GitHub is far from resembling a tool that lets us review our annotations.
I do, however, encourage you to track your annotations with Git & push them to GitHub.
git add annotations.json
git commit -m "Add baby yoda annotations for season 2"
git push
The Ugly
OK, we understand there are things entirely outside of GitHub’s scope. But what about the grey area? Even within the constraints of Git Versioning and PRs, ML workflows often break on GitHub.
You may want to use Git to track your notebooks (very good idea btw!), or a text-based, moderately sized dataset. While both are possible with GitHub, the experience is less than ideal.
Review Notebooks
GitHub actually supports viewing notebooks. However, when diffing, it treats notebooks just like any other code file and tries to show a diff of the underlying JSON of the notebook.
This is not useful to actually see what changed, especially if you want to compare rich outputs like graphs, images, etc.

Viewing & Diffing Non-Code files
GitHub supports some non-trivial, non-code files, well done!
On GitHub, you can view images, 3D files, CSVs, PDFs, and more! If these are the only file types you care about — and you don’t have so many that they overload Git — then GitHub will work just fine! 😄
But wait a second… Some really basic file types are missing like audio & video as well as the ability to see file metadata.
Further more, diffing only works for code, images and 3D files (let me know if you find other supported file types). This makes sense, though, as GitHub wasn’t really created specifically for machine learning projects. DagsHub is a platform that was made with data scientists in mind, so diffing various kinds of data is one of the big missing parts it adds to the equation.
Conclusion
Although GitHub can be a great tool for collaboration on ML projects, it is missing some key features. Luckily, a lot of open source tools are built on top of Git and allow us to connect our ML ingredients to our Git repository.
At DagsHub we took an approach similar to GitHub, and built a platform surrounding open source tools like Git, DVC, MLflow, Label Studio (and more to come) to help you collaborate on open source ML projects 😊
Connect your GitHub repository to DagsHub today and enjoy a free fully setup DVC & MLflow servers.


