


Layered Neural Rendering for Retiming People in Video
Have you heard of film reshoots? During movie / TV show editing, there are a lot of situations wherein shots are either out of place, equipment is in the shot or something similarly disastrous - to the point where the entire scene needs to be filmed a second time. That's where the millions go.
Imagine being able to make these fixes, with longs shots containing a lot of noise and occlusion! In 2020, the VGG Lab at Oxford University did just that, with their paper: Layered Neural Rendering for Retiming People in Video, and it's absolutely incredible.
 google
googleResearch Objective
Let's look at the technical definition of retiming:
Retiming is the technique of moving the structural location of latches or registers in a digital circuit to improve its performance, area, and/or power characteristics in such a way that preserves its functional behavior at its outputs.
In normal people terms, we're basically looking to adjust (or even remove!) timings between critical components within a given video.
Broadly this paper achieves this by decomposing a video feed into layers. This layer contains not only the actual individual, but also causal components within the video feed - basically everything the user interacts with. Their paper, in the process of retiming video, utilizes and expands upon research in a broad set of domains - including:
- Manipulating Human Poses in Video
- Image and Video Matting
- Video Layer Representation
- Neural Rendering
- Camera Tracking
- Result Upsampling
Here's a cool demonstration of the incredible results obtained from this architecture:

So, how does it work?
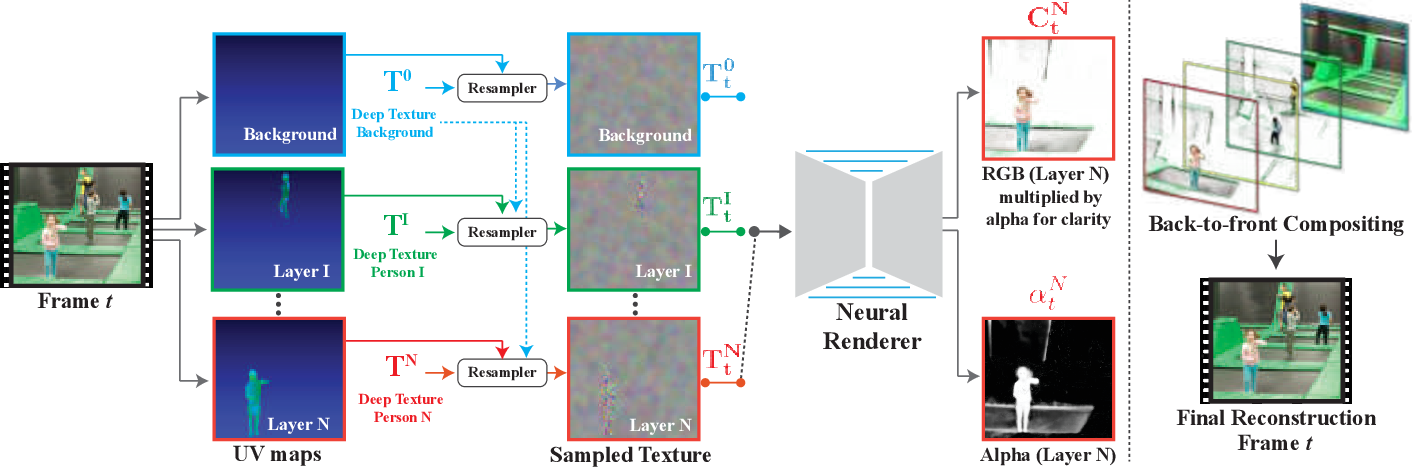
Let's first describe briefly the standard pipeline run on a target video from start to finish. First, the input video is split into layers based on their RGBA configuration. These are then updated to associate to individuals. Full-body UV maps are built using pose estimation techniques against the occluded and disoccluded sections of people in video. Once each individual is explicitly modeled, the system independently determines any features influenced by said subjects in the video. For example, a person's shadow trails them as they translate across the screen. If the shadow is not retimed but the individual is, the output video aberrates and therefore unusable. Remarkably, the feature mapping is a learned representation, and doesn't require external modification beyond initial training. These learnt features are texture maps.
These texture maps with the sampled background is now passed to the neural renderer. The neural renderer is the focal point of the system. Using the texture maps, the renderer learns correlated scene features, returning layer representations for each subject to be retimed in the video.
The RGBA maps are now combined with conventional back to front compositing, where the final output is obtained by consecutively stacking layers on top of one another. We now have our output video, decomposed by correlation. We can then feed this into a standard video editing application to adjust the layer timings, to either align or fix video! The technical term for this is 'magic'.
Development
Now that we have a good overview on a single-run pipeline, let us refer to individual factors that have contributed to the development of the target system.
It is interesting to note that this system does not explicitly synthesize new poses.
The following subheadings are presented in order of use and elucidates both the complexity of the problem and the intuition fueling the solution.
Image and Video Matting
The first objective is to develop the input for the neural renderer. This involves splitting the video into layers for each person. This paper proposes bifurcating these by building an UV map of an image. Off-the-shelf methods for this however do not produce full body maps in frames where the target individual is partially or completely covered by other people or objects. This was remedied by modifying the pre-trained framework to produce full body UV's, approximating body features to keypoint estimation methods; these did not require any further modification. Note that at this stage, our layers only have the person mapped and not their correlated features such as shadows or reflections. These UV maps are then resampled to produce deep texture maps, which serve as inputs to the neural renderer.
Neural Rendering
The neural layer takes the provided person maps and a static background. The objective of the neural renderer is to attach to corresponding layers the remaining correlated elements as previously described. It is then tasked with recreating the full video from the provisioned feature-complete layers ground up, the convergence of loss functions estimating optimal performance. Each layer is computed in a separate forward pass and are not interrelated. We will further elaborate on the loss function when describing the training regime for the system.
The renderer network assigns specific features to the respective individuals using fundamental properties of Convolutional Neural Networks, namely the fact that correlated elements require smaller changes to the model weights than unrelated elements. Therefore, the network first reconstructs the correlating features, using a separate bootstrapping framework (which we'll get to in a second).
Camera Tracking
So far, we have referred the background layer to a static image. However this is not the case for most footage in practical, real-world scenarios - the following describes the proposed solution to provide the optimal output even during such cases.
Minor Stabilization
Handheld footage often shakes throughout the course of the video. This can offset results. To mitigate this, the background layer is composited from all available frames, the subsequent reference frame then used to stabilize the video.
Perceptible Panning
In case of intentional camera panning, the above technique cannot work. Instead, the camera movement is estimated from frame-to-frame, and assigned data points on a coordinate system (x, y, z). This coordinate system is then utilized when building the UV maps, and the original camera motion is preserved.
Result Compositing
The result is back to front composited. You could interpret this like a stack of paper, you first place the background, and then the person furthermost from the camera, and so on and so forth, climbing up the layers until a full image is provided.
The neural renderer construction that is output however lacks detail, as it is trained on low-resolution video taking into consideration heavy computational costs. It only retains core motion structure details. Therefore the original video is once again used for detail deconstruction which is then applied onto each layer during compositing. Through the upsampling network, the images maintain their original detail as they are retimed. Do note that here, occlusions are not rectified and as a result the occluded regions contain previously described estimates of core motion and structure details.
The authors of this research have also built an interactive tool that allows adjustment to fine tune the retiming of tracked features, as well as the removal of individuals from particular frames by dropping target individual layers. Layers can also be freeze-framed for specified amounts of time using said interactive tool.
Training Regime
One of my favorite components of this research is how they engineered their loss function.
Training loss is split into three sub-functions, namely: reconstruction, mask and regularization errors. The combination of these as described in the below equation provides the final error loss.
$$ E_{total} = E_{recon} + \gamma_mE_{mask} + \beta E_{reg} $$
As non-linear optimization is applied in the following, the applied weights impact adversely produced results. We will elaborate on the use and influence of these in the individual loss functions as elaborated below -
Reconstruction Loss
Since an essential objective of the renderer is to successfully reverse engineer the target image from the source, it is crucial to ensure this is minimized.
$$ E_{recon} = \frac{1}{K}\sum_t \left \| I_t - Comp(L_t, o_t) \right \|_1 $$
Regularization Loss
Regularization methods are used to help an optimization method to generalize better. This principle carries forward to this proposed method also, and intended to encourage distinct variation in the alpha layer.
$$ E_{reg} = \frac{1}{K}\frac{1}{N}\sum_t \sum_i \gamma \left \| \alpha^i_t \right \|_1 + \Phi_0(\alpha^i_t) $$
Bootstrapper for Mask Loss
The term bootstrapper does not directly confer to the traditional definition of a bootstrapper, instead playing on the definition in the sense that it is an initial run fundamental to system success. The framework purposefully overfits the image to the target network, as a result of which the effects of feature reconstruction are exemplified. Overfitting causes correlated elements to be learnt far quicker than independent elements, whereas the lack of a gradient motivates the system to attach those elements to different layers. This generates the target layer representation.
A heavy weight is initially applied to ensure it is this weight that reduces first so that network develops it's biases towards a plausible solution. Then, it slowly reduces, eventually completely being turned off as it converges with it's local minimum.
$$ E_{mask} = \frac{1}{K}\frac{1}{N}\sum_t \sum_i D(m^i_t, \alpha^i_t) $$
Detail Upsampling
The resultant output post neural rendering lacks a lot of detail. They got around this using a conventional upsampling technique: by take the residual to the input video, and applying that to the layers, some of the detail is recovered.
Conclusion
Really, that's about it! If you found this interesting, check out their paper, website and source code. It's fantastic.
Acknowledgements
Thanks @Jacob Zietek for the awesome feedback on the blog draft!


