数据集处理
原始数据集
One CSV file, arg_quality_rank_30k.csv, contain the following columns for each sentence:
- argument
- topic - the topic context of the argument
- set - either train, dev or test
- WA - the quality label according to the weighted-average scoring function
- MACE-P - the quality label according to the MACE-P scoring function
- stance_WA - the stance label according to the weighted-average scoring function
- stance_WA_conf - the confidence in the stance label according to the weighted-average scoring function
原始数据集集为:arg_quality_rank_30k
数据集翻译
我们利用GPT-3.5-turbo将原始的英文论证和论点翻译成了中文
Total Token used:5535770 ,由于是翻译任务,输入输出token数差不多,因此大概花了不到六美刀。
最终翻译获得的数据集为:arg_quality_rank_zh
两类评分 WA 和 MACE-P
WA(Weighted-Average)和MACE-P分别适合以下应用场景:
WA(Weighted-Average):WA适用于需要考虑注释者可靠性的应用场景。它通过将注释者的可靠性纳入评分函数,减少了非可靠注释者对最终质量评分的影响,从而提供了一种直观且逐步的数据清洗方法。WA倾向于呈现一个渐进的连续尺度,而不是像MACE-P那样试图发现“真实”的二元标签。因此,在本质上推导出非二进制分数的任务中,我们更倾向于使用WA作为评分函数。
MACE-P(MACE Probability):MACE-P适用于需要发现“真实”二元标签的应用场景。MACE是一种无监督的项目响应生成模型,它根据给定的注释预测每个标签的概率。由于MACE为两个标签都分配概率,因此质量评分倾向于两个极端值,形成U型直方图。这使得MACE-P更适合那些需要确定哪个参数更好的任务。
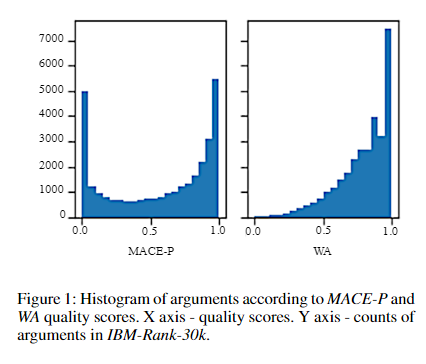
训练数据集
基于以上分析,我们选取了WA评分,并将其与翻译获得的中文数据集进行了拼接获得了一个,包含论证,论点,数据类型和WA评分的数据集。
微调BERT
BERT-Finetune(以下简称BERT-FT)。该方法对BERT的预训练模型进行微调。BERT10的官方代码库支持将微调应用于分类任务,通过在BERT模型的最后一层的[CLS]标记上应用线性层,然后通过softmax层传递。前面层的权重使用BERT的预训练模型进行初始化,然后整个网络在新数据上进行训练。为了将微调过程适应于回归任务,执行以下操作:(1)将标签类型更改为表示实数值而不是整数;(2)用sigmoid函数替换softmax层,以支持范围在[0,1]内的单个输出值;(3)修改损失函数,计算logits与标签之间的均方误差。
BERT-FT_TOPIC。我们还评估了将主题添加到BERT-FT输入中的效果。主题与参数连接在一起,用[SEP]分隔符分隔,并像BERT-FT一样进行微调。
微调LLM
试着通过微调LLM来实现评分系统。主要和英文数据集的Project Debater做对比,对比指标为:
- 原始分数与标签分数MAE, MSE, RMSE。
- 将0到0.3定义为低质量类型,值为-1,0.3到0.7为中等质量类型,值为0.7到1为高质量类型,值为1。计算这种情况下的MLAE, MLSE, RMLSE和错误分类数Wrong_time。
- 将差距在0.1之内的算作小误差,0.2到0.1的为中等误差,0.2以上的为大误差,计算三类误差的数量
商业大模型
微调了3个epoch的GPT-3.5-turbo,可能是因为轮数太少效果差Project Debater很多。
微调了16个epoch的Spark-3.0,效果非常好,中文方面远超,几乎与Project Debater的英文方面相差无几,可惜会有8%左右概率的敏感词问题.Spark-3.0微调的英文效果也与PD相差无几,而且几乎不会出现敏感词问题。


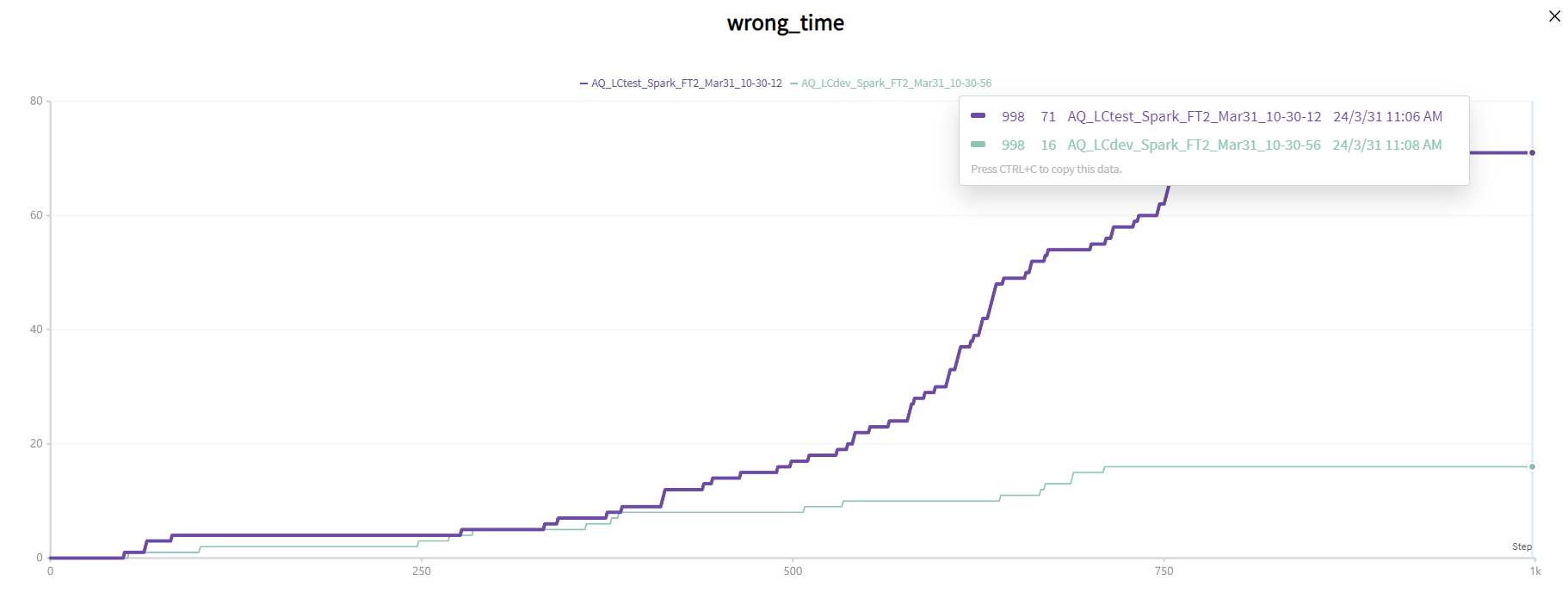
开源大模型
试着微调了7B的intern2,效果完全不行。


 KashiwaByte
KashiwaByte
 DVC
DVC



