


Grokking Large Language Models
LLMs like GPT are incredibly fluent in English, and wield it powerfully. Modeling this confidence in language for subject-matter expertise isn’t logical yet an easy assumption to make. Below is one such example of a failing case, adapted from my favorite deep learning class at university. Feel free to follow along!
To start, here's a quick example of an LLM prompt from Google:
Convert Python to Javascript.
Python: print("hello world")
Javascript: console.log("hello world")
Python: $USER_INPUT
Javascript: $LLM_OUTPUTHere, $USER_INPUT denotes the arbitrary string set by someone using the LLM. The LLM uses the instruction as well as the few examples at the beginning as a cue for the task it was supposed to predict as well as the format of the response. It's an example of few-shot learning. Exactly why this works is very interesting, and we'll get to it in a second. For now, let's experiment with our own prompt setup, similar to the one by Google, on the T5 (by Google!):
from transformers import pipeline
prompt = \\
"""Logically conclude the incomplete sentence.
All men are mortal. Socrates is a man. Therefore, Socrates is mortal.
All programmers are happy. Alice is a programmer. Therefore, Alice is happy.
"""
user_input = "All elephants are heavy. Pinocchio is a toy. Therefore, Pinocchio is" # consider this as an example user input
model = pipeline(model='google/flan-t5-base')
print(model(prompt + user_input))
The task we've setup is straightforward; the bot is provided a few examples of commonsense logic, and it must predict the following few tokens. Clearly, we haven't provided the information within our context to answer accurately, but it is pre-trained on a massive corpora of text. What do you think the model predicts?
Here is what I got:
>>> print(model(prompt + user_input))
[{'generated_text': 'heavy.'}]
I also tried this exact experiment with xlm-roberta-large, appending ' <mask>.' to the user input. The first result, with the highest score was:
{'score': 0.4857480823993683,
'token': 99162,
'token_str': 'heavy',
'sequence': 'Logically conclude the following incomplete sentence. All men are mortal. Socrates is a man. Therefore, Socrates is mortal. All programmers are happy. Alice is a programmer. Therefore, Alice is happy. All elephants are heavy. Pinocchio is a toy. Therefore, Pinocchio is **heavy**.'}
This is also used to apply to ChatGPT. However, since they are trained adversarially, it now responds with ‘Therefore, Pinnochio is not heavy’ - still not correct, but atleast better than before. We can still find this artifact on their legacy models:
>>> openai.Completion.create(model='text-davinci-002', prompt=query)
<OpenAIObject text_completion id=cmpl-7alyWTUFWkVykHl0bEjurCmjDBJ7t at 0x69ca87210a70> JSON: {
"id": "cmpl-7alyWTUFWkVykHl0bEjurCmjDBJ7t",
"object": "text_completion",
"created": 1688998580,
"model": "text-davinci-002",
"choices": [
{
"text": " heavy.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 60,
"completion_tokens": 2,
"total_tokens": 62
}
}
The obvious question at this stage likely is: 'Why did this fail?' The line of reasoning is clearly not the same as the previous examples, yet the prediction for the token it is most confident for is incorrect.
One reason for this is the fact that we introduce out-of-distribution(OOD) testing to the LLM. Our current neural-network paradigm uses conditional probabilities to systematically update it's beliefs. While this models complex distributions with millions of dimensions effectively, it does not allow us to effectively extrapolate beyond the distribution. That is why, when we gave it an input it had not seen, the model output was unreliable.
I find this an interesting primer to what in my opinion is the biggest hurdle that every practical application of LLMs needs to contend with today -- hallucination. The explicit objective function of LLMs is mastering language (hence; Large Language Models). Being correct about a question is simply a by-product of sounding confident and fluent. It doesn't have an understanding of what an 'elephant' is, or what the word 'heavy' means. Neither does it care to identify adjectives, articles, pronouns, verbs, nouns, or any other artifact of the language. It simply models the language conditionally, and returns the output that best fulfills it's objective.
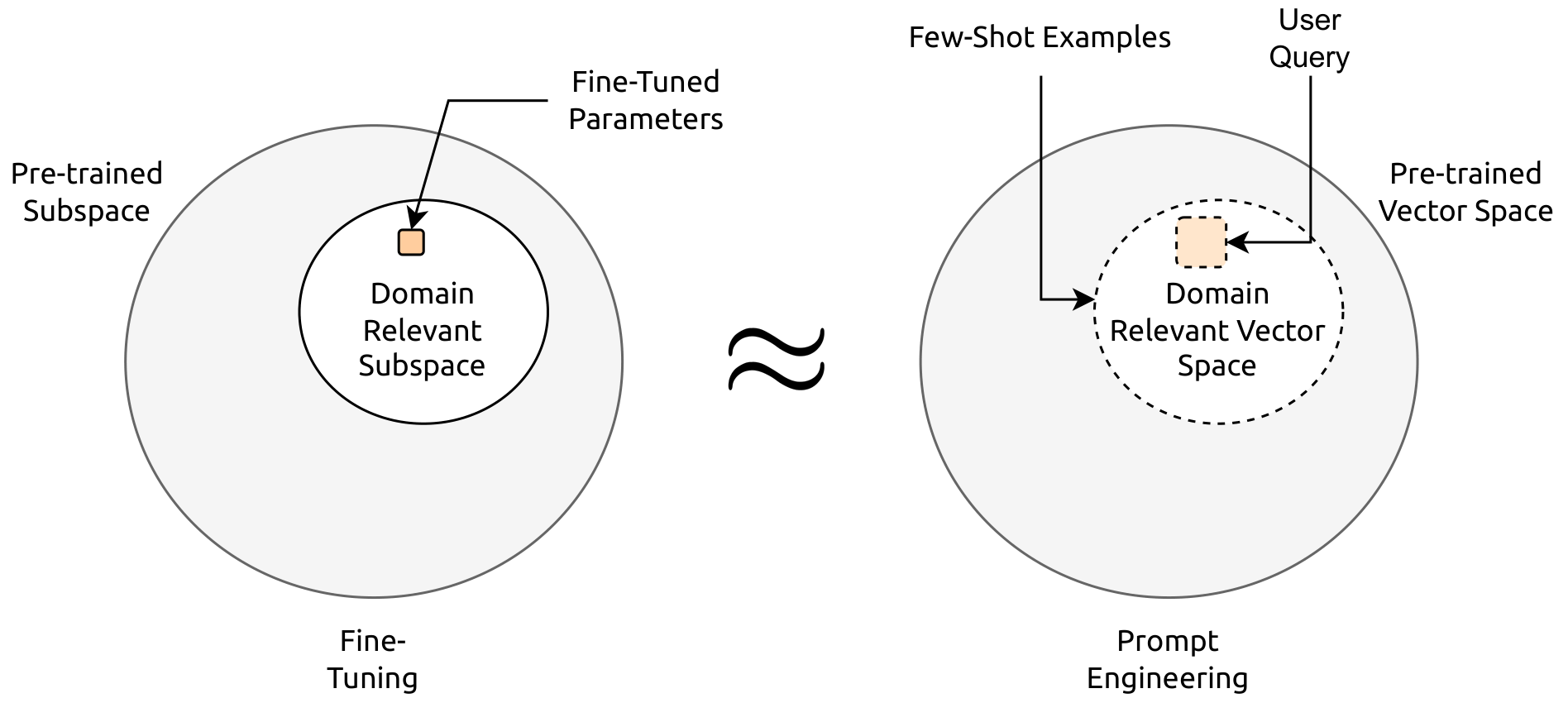
So, why is Prompt Engineering even a Thing?
For this, let's talk about Hypothesis spaces. The Hypothesis Space of a given neural architecture is the set of all the models that can be obtained with every permutation of it’s parameters and hyperparameters. It is a concept relevant to meta-learning (learning to learn) that LLMs leverage, that allows us to use them generalizably on a large set of tasks. Out of all the possible hypothesis spaces, the subset wherein the model performs optimally on a task is incredibly large. All the evaluators and losses we use return ideal metrics for the task. In such a situation, which set of weights are the best?
The solution is to use this first hypothesis subset as a prior for a different task, the idea being that by finding a set of weights that can perform optimally (more practically, appreciably) on multiple tasks, it's performance on unseen data on the first task will be better than that of a set of weights randomly picked from the optimal hypothesis space on the given data.
The way I understand it, setting up model prompts enables a rudimentary version of the same phenomenon. where self-attention, allows 'fine-tunable' input, with co-referencing can allow different latent sets of information to be utilized. The prompt is effectively us picking the subset within which we would like the large language model to operate. Since the base subset (predicting words for a given language) is so large, it is able to handle a massive-range of domain specific tasks without being explicitly trained on it.
A compounding aspect of this is the cost overhead. We’ll discuss efficiently fine-tuning LLMs further, but even that requires atleast 24GB VRAM. AWS’ g5.xlarge EC2 instance offers an NVIDIA A10G, at $1.006/hr; significant in the medium and long term.
Large Language Models and Licensing
Another unanticipated challenge with using Language Models is it’s licensing aspect. Many open source language models - like LLaMa - does not come with a permissive license. As a consequence, while they can be used for research, it isn’t allowed to be used for commercial purposes. This is pretty restrictive for real-world application, and is something that needs to be considered when picking which LLM to use.
Falcon and MPT are two fantastic language models that have permissive licenses, and deserve a massive shoutout for being so awesome. 😎
Fine-Tuning Language Models
One and few-shot learning is susceptible to significant failure cases dependent largely on their training sets. Using public language models for obscure downstream tasks without fine-tuning introduces out-of-distribution inference. Consequently, this confounds situations such as the one in the beginning, and the models is not usable in a production setting.
For such a situation, it is expensive but possible to effectively fine-tune models. Below are a couple of one-liners of papers/libraries useful for fine-tuning:
Less Is More for Alignment (LIMA)
LIMA highlights the importance of good data. Their fine-tuning procedure uses only 1,000 carefully chosen samples using pre-trained LLaMa as it’s base, however, it is able to outperform closed-source SOTA models on tasks it was aligned to. Furthermore, the authors also do mention that LIMA also is an effective fine-tuning solution for cases wherein the tuned task is outside the original training distribution.
This is especially relevant to a production setting, given it highlights the utility of an active learning pipeline for fine-tuning a model on a task with significant improvement over contextual learning in the long term.
Low Rank Adaption (LoRA)
The generalizability of large language models foundationally requires rapid learnability - i.e. minimal fine-tuning should quickly converge to an updated task description - as LIMA proved. Aghajanyan et al. (2020) shows that the minimum required dimensionality to perform appreciably on complex tasks is low. LoRA exploits this, configuring weight updates as the matrix multiplication of two low-rank matrices - defined as
$$W_n^{d \times k} = W_{n-1} + \delta W = BA \text{, where } B \in M_{d \times r}(\mathbb{R}),\ A \in M_{r \times k}(\mathbb{R})$$
To efficiently perform weight updates on trainable attention or feedforward layers.
LLM.8bit() (BitsAndBytes)
BitsAndBytes is a quantization library that wraps CUDA to allow loading lower-precision weights to transformer models without performance degradation. It leverages mixed-bit precision, by first splitting the two matrix operands from it’s respective outliers. Outliers in this case are matrix elements with high values. These are then multiplied in a higher 16-bit precision, whereas the lower bit precision is multiplied with 8-bit precision. These are then accumulated to setup the final output.
BitsAndBytes can be used effectively in tandem with LoRA to fine-tune quantized LLMs with performances representative of full-range fine-tuning!
Parameter-Efficient Fine-Tuning (PEFT)
Bringing the above ideas together, PEFT is a fantastic library by HuggingFace, that streamlines (as the name suggests) fine-tuning LLMs obtainable through model cards on transformers. It provides a straightforward interface to using techniques like LoRA or Prompt Tuning. BitsAndBytes integrates by design to any transformer architecture.
Since it uses transformers.Trainer for facilitating fine-tuning, it also supports all of it’s associated goodies - like DagsHub’s data, experiment and artifact integration - by default. The metrics on the package’s repository is a good reference for the improvements you could expect using the techniques they support.
Acknowledgements
I'd like to thank @Dean Pleban for the constructive reviews, feedback and input throughout the entire writing process, and to CS690-DPL by Prof. Bruno Rebeiro for the OOD evaluation experiment.


