Image Embedding: Benefits, Use Cases, and Best Practices
- Ignacio Peletier
- 11 min read
- a year ago
Senior Data Scientist at Busuu. Telecommunications engineer specializing in Data Science and Machine Learning. | Senior Data Scientist

Introduction
The rapid advancement of image processing over the past decade is no coincidence. Images are ubiquitous and among the kinds of data with the highest dimensionality we can work with. The key to success in managing images lies in extracting the most relevant information.
The concept of image embeddings has become a cornerstone in modern machine learning strategies, allowing a more nuanced and efficient handling of image data. Unlike traditional methods that often struggle with the complexity and volume of image data, neural networks have proved remarkably adept. By transforming high-dimensional image data into a compact, lower-dimensional, and meaningful representation, image embeddings facilitate easier and more effective analysis. This can lead to enhancing accuracy but also increasing the efficiency of downstream tasks such as classification, retrieval, clustering, and anomaly detection, to name a few.
This article explains image embeddings and the technology that powers them while presenting industry use cases and best practices to implement image embeddings in your organization.
What is Image Embedding?
At its core, image embedding, also referred to as latent vector or representation, is a technique that transforms high-dimensional image data into a more manageable, lower-dimensional numerical representation. This transformation retains crucial information about the original content while discarding redundant or less informative data. Image embeddings are extracted using sophisticated machine learning models, specifically deep neural networks.
Multiple goals are achieved:
- Dimensionality Reduction: By condensing information, embeddings make complex data easier to analyze and process.
- Feature Extraction: Embeddings highlight essential features of images, facilitating more nuanced insights and applications.
- Similarity Search: On top of this, embeddings form a continuous space such that similar images are embedded in similar vectors.
The next step usually involves using these embeddings in machine learning, as inputs to predict a desired metric or KPI to solve a business need or perform an analysis with a more handleable dataset due to the reduced dimensionality. In some cases, learning the embeddings is the key part of a machine learning system. For instance, in few-shot learning (Medium: A Guide to few-shot Learning with embeddings), the embeddings enable the classification of classes in the training dataset with not many examples present, sometimes with as little as one example, thanks to the close distances in the embedding space.
The following diagram illustrates the transformation from an image to a latent vector, via an embedding model. The image input has 78000 dimensions (200x130x3) while the embedding output has the arbitrarily chosen size of 768, representing a reduction of approximately 99%.
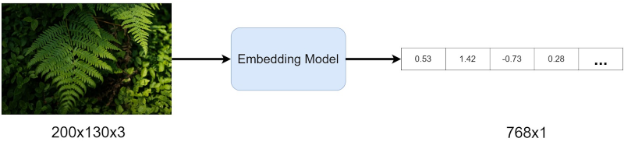
The dimensionality of the embedding is a design parameter, offering a trade-off between the model size and the information that the embedding can store. Its size must be decided depending on the use case.
The Technology Behind the Tool
Image embeddings are powered by advances in deep learning, particularly through the use of Convolutional Neural Networks (CNNs); great advancements have also come with Transformer architectures. These technologies excel in analyzing visual inputs by emulating hierarchical processing techniques.
- Convolutional Neural Networks: CNNs are built with layers of filters to capture spatial relationships in images, extracting features like edges and textures at lower layers and more complex concepts at higher layers.
- Transformer Models: Originally designed for natural language processing, transformers have been adapted to vision transformers (ViT) and are now used for image analysis. They have proved to yield better results than CNNs in some applications.
While ViTs outperform CNNs on many occasions, especially on bigger datasets, they come with the trade-off of increased computational requirements.
Embeddings are often extracted as the output of a neural network layer from a task-specific model, such as the inceptionV3 classifier. They can also be extracted from models specifically designed and trained to learn embeddings, such as CLIP (Contrastive Language-Image Pre-training, CLIP: Connecting text and images).
We follow with a comparison between some of the commonly used image embedding models:
- VGG-16: trained on the ImageNet dataset (14 million images and 1000 classes). It is a CNN model for Large-Scale Image Recognition. The last layers can be used for extracting rich image embeddings with 512 dimensions. It has 138 million parameters.
- ResNet50: having a residual architecture, ResNet50 is a smaller model than the previous one with only 25 million parameters. The output of the last layers produces embeddings with 2048 dimensions.
- InceptionV3: just a bit smaller than ResNet50, InceptionV3 is another powerful CNN that can be used for creating image embeddings of the same size.
- MobileNetV2: if the application at hand requires fast computing time, the resources are limited or we want to compute embeddings on-device. MobileNetV2 is a good candidate for computing image embeddings. It has only 3.4 million parameters and it can be used to extract embeddings of 1280.
- Vision Transformer: if computing time is not a problem or accuracy is critical, ViTs can prove to be useful. There are three models available that vary from 86 to 632 million parameters. The embedding size for the smaller model is 768.
Experimentation will be needed to choose the optimal model given the requirements of your task at hand.
In the next section, we'll explore how these technological advantages translate into tangible benefits for your teams and projects.
Benefits of Image Embeddings
Image embeddings offer a transformative advantage over traditional image processing methods. These traditional methods involved manually extracting features for images which were used as descriptors, and then these were fed to machine learning models to make predictions, classifications, or perform clustering. These features were engineered given domain knowledge and were tailored for the specific task at hand.
A great example of traditional image features is SIFT (Scale Invariant Feature Transform) which is a quite involved algorithm that finds key points in images:
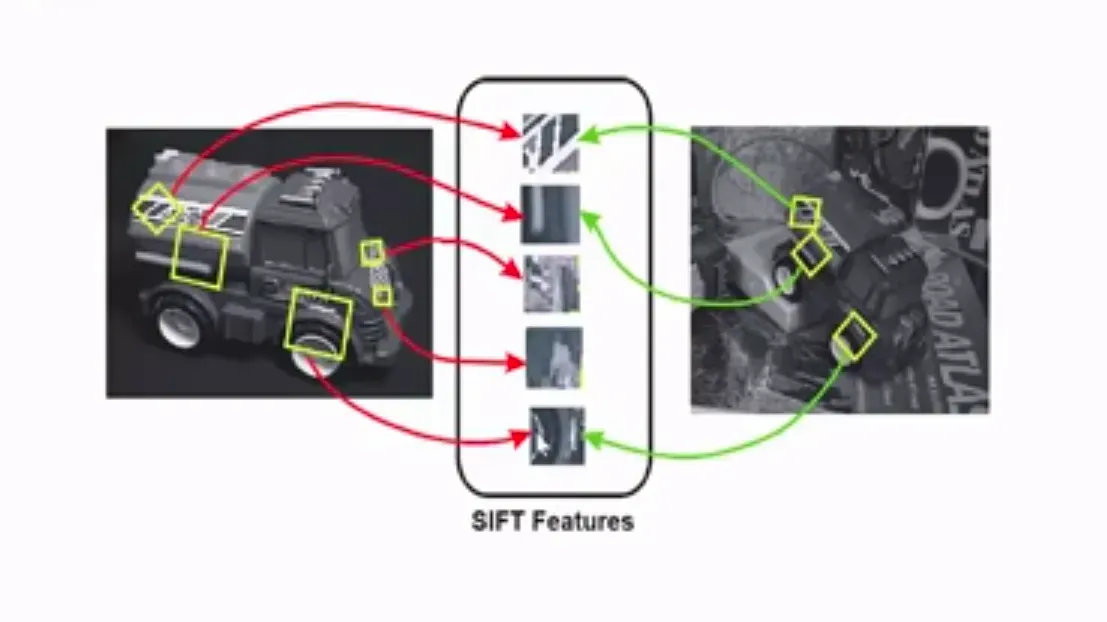
By leveraging image embeddings, all the weight lifting of feature extraction is done by a neural network. This way the team’s effort can be spent on solving the business’ needs.
Here are some reasons why integrating image embeddings into your workflows can significantly enhance your team's efficiency and analytical capabilities:
- Increased Accuracy: Image embeddings capture the essence of images by distilling them into a compact, feature-rich numerical representation. This can lead to higher accuracy in tasks like image classification and clustering due to the fact that noise and unnecessary information are reduced.
- Increased Efficiency: Due to the reduced dimensionality, image embeddings can significantly speed up the data processing time of the following tasks. This is especially beneficial in environments where quick decision-making is critical, such as in real-time systems.
- Scalability: working with data of lower complexity enables handling larger volumes of data and lowers the computational resources required, reducing costs.
- Improved Data Visualization: Embeddings allow for the visualization of complex image datasets in reduced dimensional spaces.
Image embeddings also enable techniques such as few-shot learning. In which a machine learning algorithm is trained with a small dataset, in this case made of embeddings. This works because similar images have really close latent representations, making algorithms generalize better.
Industry Use Cases
Image embeddings have found their way into various industry applications, proving their versatility and effectiveness in handling complex visual data. Marketing, multi-modal image search, recommender systems based on visual similarity, and face recognition in security systems are areas where embeddings can have an impact. Each of these use cases demonstrates the practical benefits of leveraging image embeddings to enhance business processes and customer experiences.

Personalized Marketing
Image clustering involves grouping a set of images into subsets (clusters) such that images in the same cluster are more similar to each other than to those in other clusters.
This is particularly useful in marketing. Images reflecting customer preferences (like styles in fashion or types of destinations in travel) can be clustered to create more targeted marketing campaigns that resonate with distinct customer groups.
Multi-modal Image Search in E-commerce
Thanks to the innovative approach of models like CLIP (Contrastive Language–Image Pre-training), an OpenAI image embedding model that leverages both text and image information in its training, images can be searched with natural language.
This technology allows for a more intuitive search experience where users can describe items they might want to buy in natural language, and the system retrieves relevant products without needing precise metadata tags. This can effectively bridge the gap between textual descriptions and visual data, making it easier for e-commerce platforms to offer a user-friendly interface that understands and responds to natural language queries:
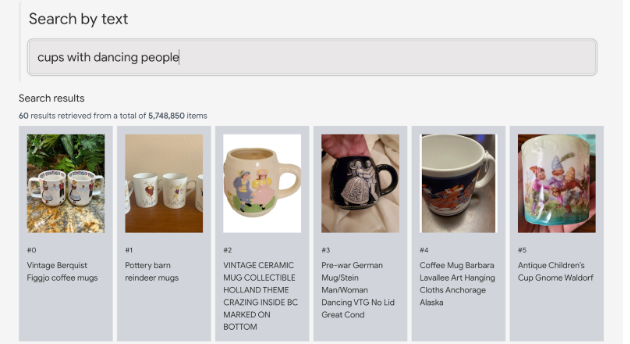
A system like this can be visualized as follows:
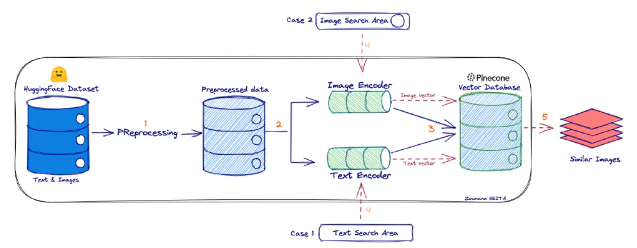
First, we preprocess an image dataset and store the embeddings in a vector database. Once a new image wants to be searched, we can use a text query that will return us the appropriate images by searching the closest image embeddings from our text query embeddings.
Visual Similarity Recommender Systems
Recommender systems are pivotal in e-commerce and streaming services, where personalized content delivery is key to user engagement and satisfaction. Image embeddings enhance recommender systems by:
- Visual Similarity: Platforms like online retail stores use image embeddings to recommend products that visually resemble items a user has shown interest in, thereby improving the shopping experience and increasing sales.
- Cross-Selling Opportunities: By analyzing the visual content of products frequently browsed or purchased together, companies can identify and promote complementary items, driving additional revenue.
The following image shows the image embedding space of an item dataset, where closer image representations in the embedding space correspond to similar items:
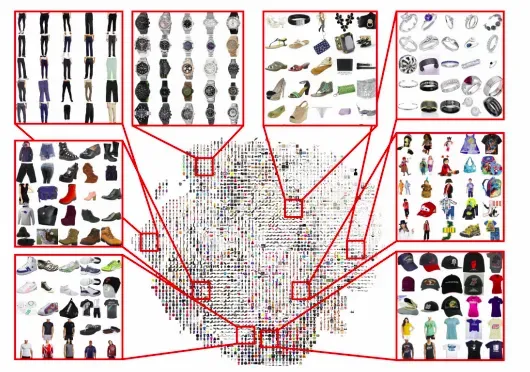
Given this embedding space, after a purchase, we could recommend new products which are close in the embedding space.
Quality Control in Assembly Lines
Image embeddings can be used to monitor products on assembly lines, detecting defects or irregularities that deviate from the norm, which enhances quality control processes. Thanks to the embeddings, the follow-up defect classifier can be trained using only examples of one class, made of good examples. This makes the model agnostic to defects, which is usually an underrepresented class whose examples can vary greatly and reduces overfitting.
Security Systems
Face recognition in security systems, where we don’t have a lot of training images for every person that needs to be recognized, can be solved using image embedding techniques.
Embeddings enable either to have a machine learning model trained with few examples (few-shot) or in some cases and depending on the scale, similarity search in the latent space is enough to reach a solid accuracy.
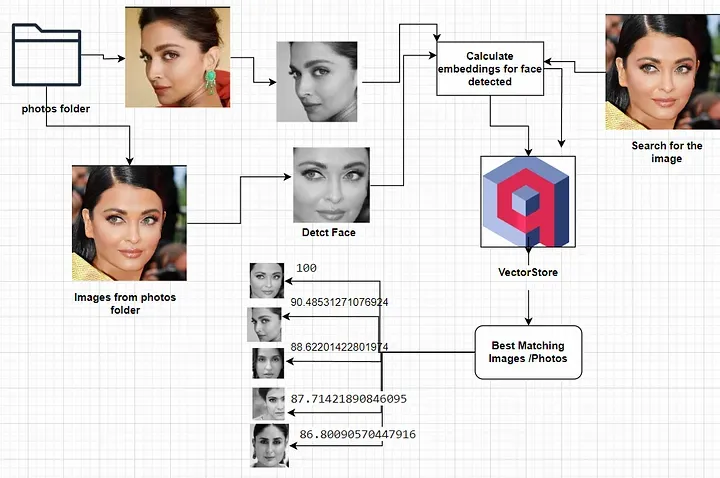
The previous system works this way: there is a bank of face images, their corresponding embeddings are stored in a vector database and the labels are also available. When there is a new example to be classified, the embeddings are extracted using similarity search in the latent space and, for example with k-Nearest-Neighbors, the new face is classified with the label corresponding to the closer matches.
As we can see, applications of image embeddings can vary. They can be applied to most of the tasks where images are the inputs. Let’s continue diving into some of the best practices when working with image embeddings.
Best Practices for Implementing Image Embeddings
When incorporating image embeddings into your workflow, the following best practices can maximize their effectiveness and streamline their integration:
Training Your Embedding Model
Before training your own model from scratch, do not hesitate to use pre-trained models to accelerate the deployment of image embedding systems. These models have been trained on vast datasets and as shown in a previous section, there are many available, offering a robust starting point that reduces initial development time.
Using pre-trained models as benchmarks for custom-built solutions can provide a reference point for performance and help identify the areas where a custom model might offer improvements.
If training is necessary and a dataset is available, consider fine-tuning an already trained model on domain data. This will reduce the work required compared to creating and training your own neural network from the start.
If you want to train your own model, as with any other machine learning-related task, data quality is key. One should always assemble high-quality and diverse datasets for training your models. Model performance is directly tied to the quality of the input data, so prioritizing data curation and augmentation is crucial.
Similarly to neural networks, decisions must be made in terms of dimensions. Carefully choose the dimensionality of the embedding space. Lower dimensions can lead to faster processing and less storage use, but too low could mean losing relevant information. Finding the right balance is key for optimal performance.
Regularly update the models to adapt to new data and evolving requirements. This includes retraining the model with new images to reflect changes in visual data and market trends.
Leveraging Self-Supervised Learning Methods
If labeled data is scarce, self-supervised learning methods such as SimCLR (Simple Framework for Contrastive Learning of Visual Representations) or MoCo (Momentum Contrast for Unsupervised Visual Representation Learning) can be valuable for training or fine-tuning an embedding model. These methods utilize large amounts of unlabeled data by creating surrogate tasks, allowing the model to learn useful representations without the need for extensive labeled datasets.
Visualizing the Embedding Space
Regularly visualize the embedding space using tools like t-SNE (t-Distributed Stochastic Neighbor Embedding) or UMAP (Uniform Manifold Approximation and Projection). This practice helps identify clusters, outliers, and any potential issues with the embedding distribution. Visualizations can provide valuable insights into how well the model is capturing the underlying structure of the data, highlight areas for improvement, and guide further tuning of the model.
Prioritizing Dataset Diversity
Sometimes, a smaller, more diverse dataset can be more effective than a larger, homogenous one. Focus on ensuring a wide variety of examples that cover the range of scenarios your model will encounter. Diversity in the training data helps the model generalize better to new and unseen data, improving its overall robustness. By including diverse samples, you can improve the model's ability to handle real-world variations and complexities, leading to more accurate and reliable embeddings.
Conclusion
Image embeddings represent a transformative approach to handling high-dimensional image data. By effectively reducing dimensionality and highlighting essential features, embeddings enhance accuracy, efficiency, and scalability across various applications—from personalized marketing and visual similarity recommender systems to quality control in assembly lines, while also enabling new use cases such as multi-modal image search. They also enable few-shot learning for training ML models, reducing the number of examples needed.
As a leader in your organization, consider the use of image embeddings in your data processing and analysis frameworks. Evaluate your current workflows and identify opportunities where embeddings could bring substantial improvements. Start simple, leveraging pre-trained models, and consider fine-tuning instead of training a full neural network for a specific case.
Consider investing in training your team to leverage this tool since it can significantly enhance your competitive edge and operational efficiency. Whether by adopting pre-trained models for immediate benefits or developing custom solutions tailored to specific needs, the implementation of image embeddings can be a game-changer if your business handles image data.



