
vilt-b32-finetuned-vqa
Description
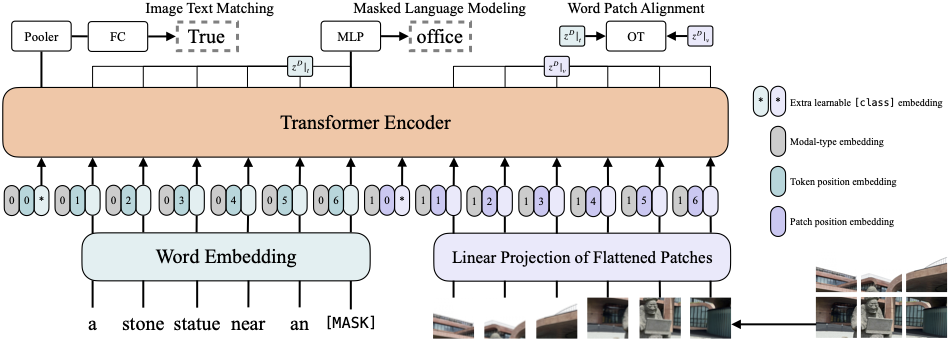
Vision-and-Language Transformer (ViLT) model fine-tuned on VQAv2. It was introduced in the paper ViLT: Vision-and-Language Transformer
Without Convolution or Region Supervision by Kim et al. and first released in this repository.
Usage
Here is how to use this model in PyTorch:
from transformers import ViltProcessor, ViltForQuestionAnswering
import requests
from PIL import Image
# prepare image + question
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "How many cats are there?"
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(**encoding)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
Pretrained Weights
You can find five pretrained weights below.
- ViLT-B/32 Pretrained with MLM+ITM for 200k steps on GCC+SBU+COCO+VG (ViLT-B/32 200k) link
- ViLT-B/32 200k finetuned on VQAv2 link
- ViLT-B/32 200k finetuned on NLVR2 link
- ViLT-B/32 200k finetuned on COCO IR/TR link
- ViLT-B/32 200k finetuned on F30K IR/TR link
License
This model is available on HuggingFace under the Apache-2.0 License.
Citation
@misc{kim2021vilt,
title={ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision},
author={Wonjae Kim and Bokyung Son and Ildoo Kim},
year={2021},
eprint={2102.03334},
archivePrefix={arXiv},
primaryClass={stat.ML}
}



 DVC
DVC